2022-04-0206:42:51,900 INFO com.dtstack.flinkx.hdfs.writer.HdfsTextOutputFormat - Close current text stream, write data size:[1563] 2022-04-0206:42:51,900 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - OutputStream for key 'warehouse/compass_2/dataland_test_db.db/test_yl_0325/.data/0.12c6031f80ede3449f01b72916912c0f.0' closed. Now beginning upload 2022-04-0206:42:51,900 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Minimum upload part size: 104857600 threshold 2147483647
2022-04-0206:42:51,946 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Getting path status for /warehouse/compass_2/dataland_test_db.db/test_yl_0325/.data (warehouse/compass_2/dataland_test_db.db/test_yl_0325/.data) 2022-04-0206:42:52,241 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Found path as directory (with /): 0/1 2022-04-0206:42:52,241 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Summary: warehouse/compass_2/dataland_test_db.db/test_yl_0325/.data/0.12c6031f80ede3449f01b72916912c0f.01543
2022-04-0206:42:52,241 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Getting path status for /warehouse/compass_2/dataland_test_db.db/test_yl_0325 (warehouse/compass_2/dataland_test_db.db/test_yl_0325) 2022-04-0206:42:52,287 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Found file (with /): fake directory 2022-04-0206:42:52,287 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Deleting fake directory warehouse/compass_2/dataland_test_db.db/test_yl_0325/
2022-04-0206:42:52,312 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Getting path status for /warehouse/compass_2/dataland_test_db.db (warehouse/compass_2/dataland_test_db.db) 2022-04-0206:42:52,384 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Found path as directory (with /): 1/0 2022-04-0206:42:52,384 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Prefix: warehouse/compass_2/dataland_test_db.db/cx_iceberg_sg_1/
2022-04-0206:42:52,384 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Getting path status for /warehouse/compass_2 (warehouse/compass_2) 2022-04-0206:42:52,451 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Found path as directory (with /): 1/0 2022-04-0206:42:52,451 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Prefix: warehouse/compass_2/dataland_test_db.db/
2022-04-0206:42:52,451 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Getting path status for /warehouse (warehouse) 2022-04-0206:42:52,533 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Found path as directory (with /): 1/0 2022-04-0206:42:52,534 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - Prefix: warehouse/Strategy_data/
2022-04-0206:42:52,534 DEBUG org.apache.hadoop.fs.s3a.S3AFileSystem - OutputStream for key 'warehouse/compass_2/dataland_test_db.db/test_yl_0325/.data/0.12c6031f80ede3449f01b72916912c0f.0' upload complete
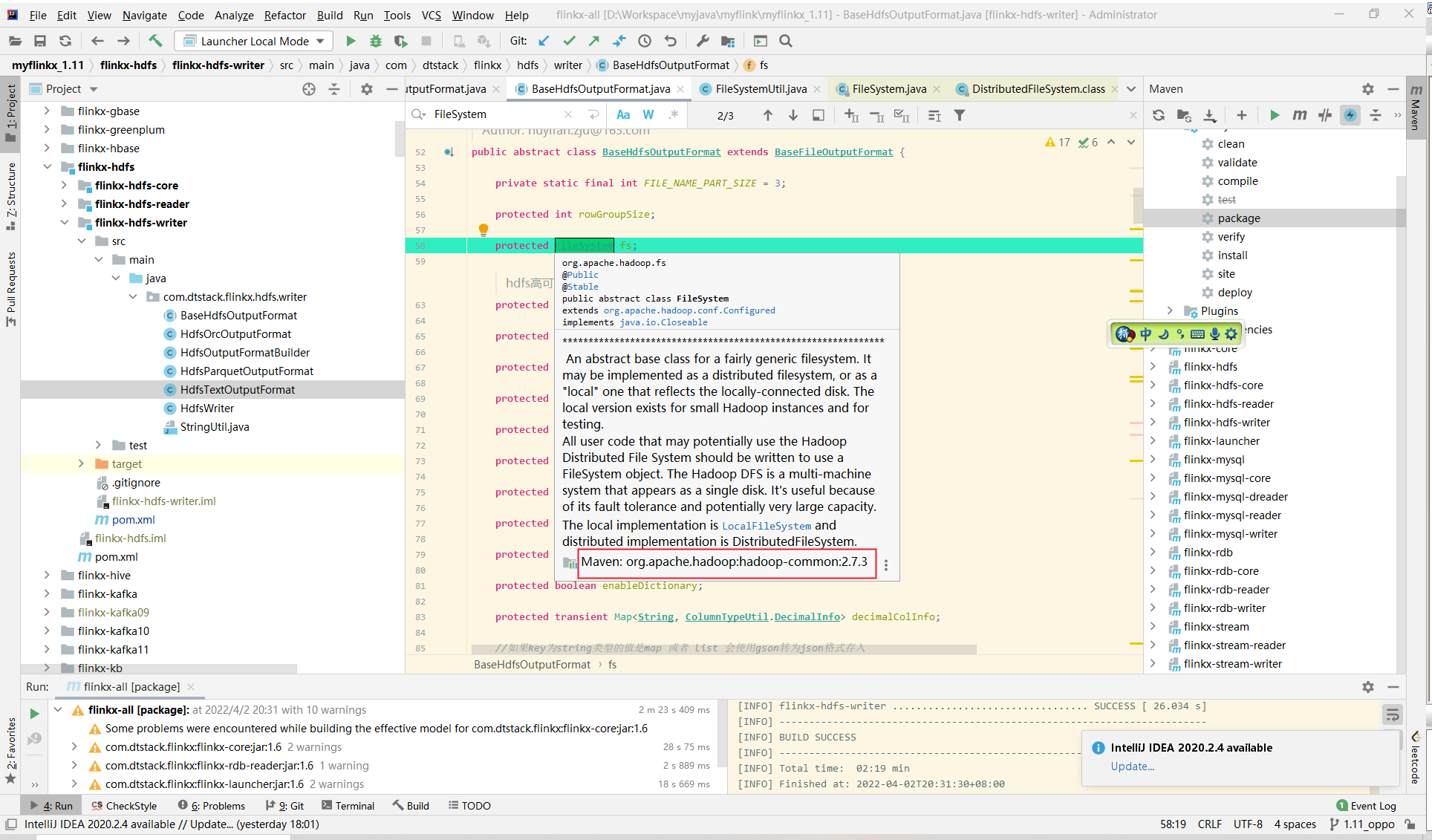
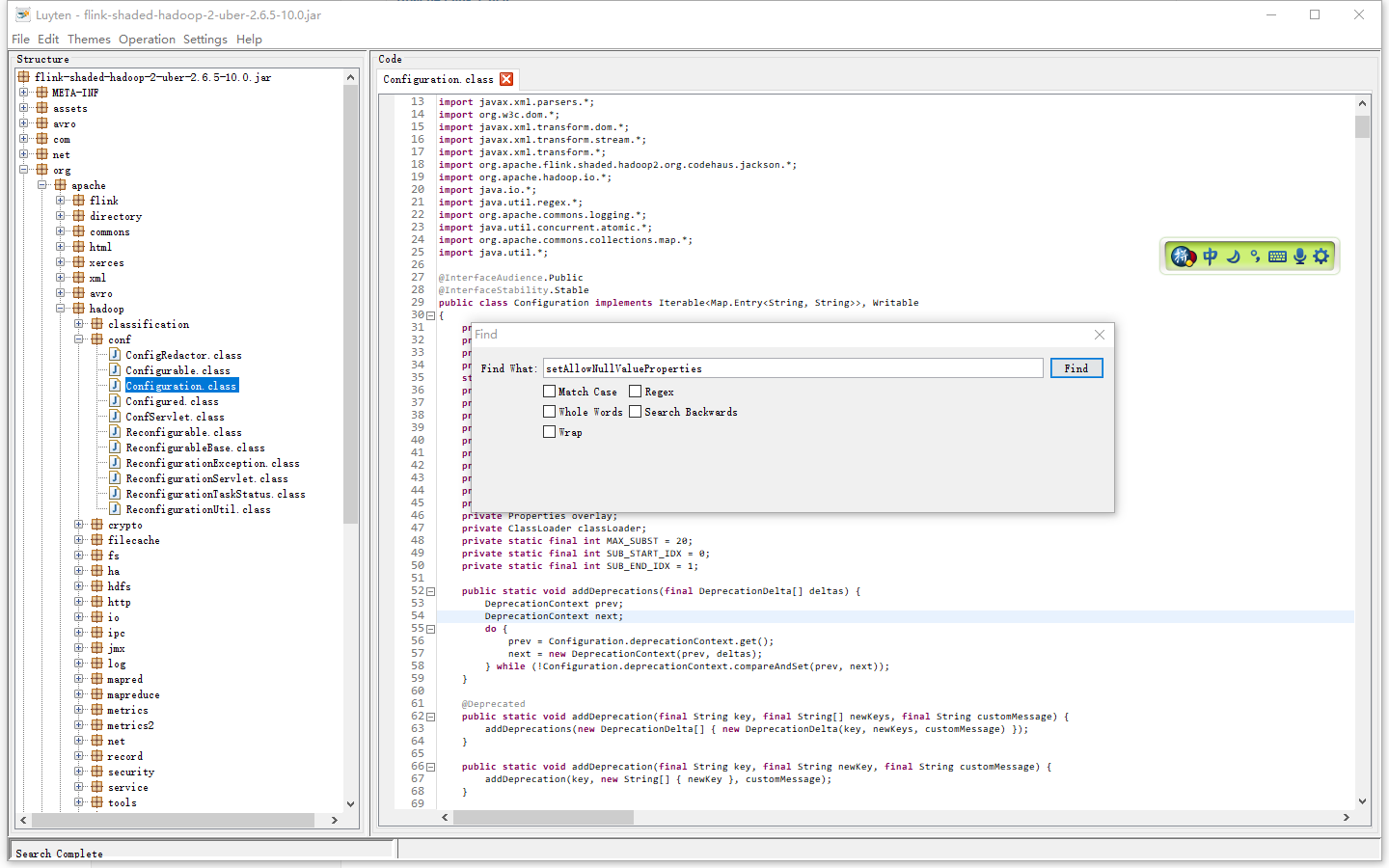
Caused by: java.lang.NoSuchMethodError: org.apache.hadoop.conf.Configuration.setAllowNullValueProperties(Z)V at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.initializeConfiguration(EmrFileSystem.java:128) at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.initialize(EmrFileSystem.java:96) at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2598) at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91) at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2632) at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2614) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:169) at com.dtstack.flinkx.util.FileSystemUtil.getFileSystem(FileSystemUtil.java:62) at com.dtstack.flinkx.hdfs.writer.BaseHdfsOutputFormat.openSource(BaseHdfsOutputFormat.java:354) at com.dtstack.flinkx.outputformat.BaseFileOutputFormat.openInternal(BaseFileOutputFormat.java:103) at com.dtstack.flinkx.hdfs.writer.BaseHdfsOutputFormat.openInternal(BaseHdfsOutputFormat.java:111) at com.dtstack.flinkx.outputformat.BaseRichOutputFormat.open(BaseRichOutputFormat.java:258) at com.dtstack.flinkx.streaming.api.functions.sink.DtOutputFormatSinkFunction.open(DtOutputFormatSinkFunction.java:89) at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:36) at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:102) at org.apache.flink.streaming.api.operators.StreamSink.open(StreamSink.java:48) at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:291) at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$0(StreamTask.java:473) at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:47) at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:469) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:522) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546) at java.lang.Thread.run(Thread.java:748)
[amy@ip-10-1-42-72 ~]$ hadoop version Hadoop 2.8.5-amzn-5 Subversion git@aws157git.com:/pkg/Aws157BigTop -r a3b61461af0d6b4d981c915b0a1f342464987aaa Compiled by ec2-user on 2019-12-14T09:05Z Compiled with protoc 2.5.0 From source with checksum fad06c90f0f460226b0a91c6c1926d4 This command was run using /usr/lib/hadoop/hadoop-common-2.8.5-amzn-5.jar