streamis 中支持批作业的一个方法
介绍如何在 streamis 中支持 flink 批作业运行。
问题
在 streamis 提交了一个 flink.sql 类型的批作业,执行的 flink sql 是
1 | SELECT 'linkis flink engine test!!!' |
执行结果失败

不过对应的 yarn application 的 FinalStatus 是 SUCCEEDED
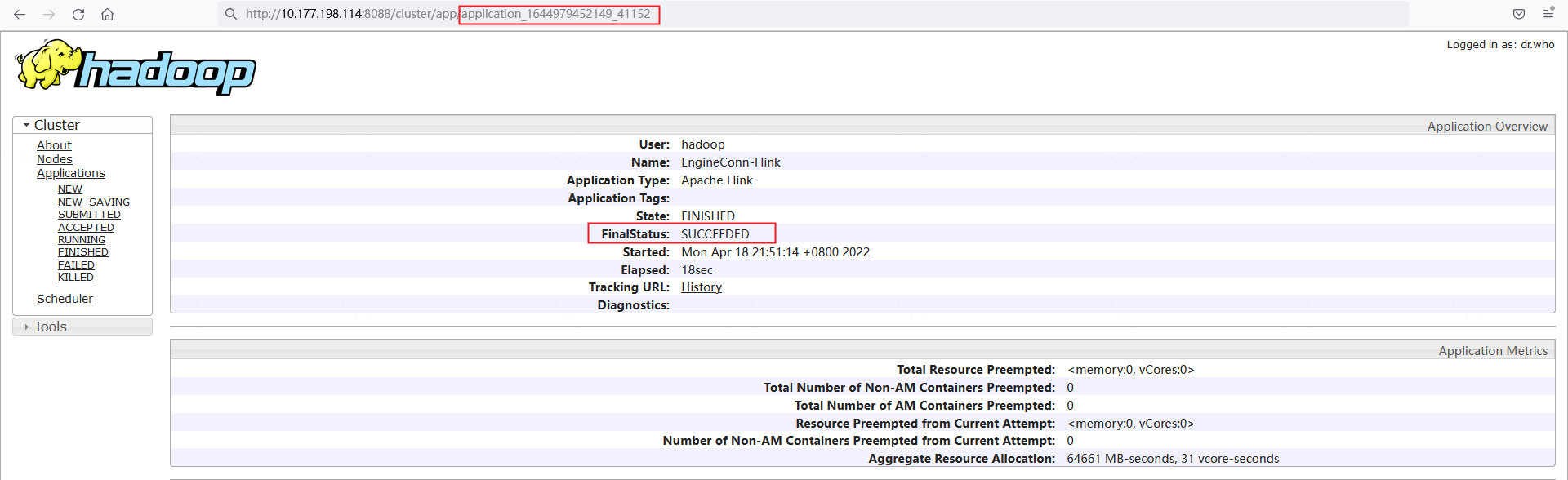
分析
streamis 提交作业的流程大致是
构建一次性作业
访问接口
/streamis/streamJobManager/job/execute,从数据库中获取 job 信息,封装到StreamisTransformJob实例 中,再经过一系列的转换(Transform)处理(添加 labels、source、作业配置、launchConfig)后得到一个LaunchJob实例。这个实例,会有 linkis 的SimpleOnceJobBuilder转成一个SubmittableSimpleOnceJob对象,封装了 linkis 客户端和引擎创建 action:CreateEngineConnAction,此外还会将作业要执行的 sql 作为资源上传到 HDFS 便于引擎执行时获取到提交创建引擎
提交上文创建的
SubmittableSimpleOnceJob,通过 linkis 客户端执行请求CreateEngineConnAction,然后在一个循环中等待引擎就绪,得到一个engineConnId。linkis 启动引擎的过程中,会创建一个FlinkCodeOnceExecutor实例的执行器,这个执行器内部会存储 yarn application id 和 作业所在 node manager 的地址。保存engineConnId和SubmittableSimpleOnceJob实例的映射到缓存onceJobs中。获取引擎信息
内部创建一个
EngineConnOperateAction,通过 linkis 客户端请求,拿到上面的 yarn application id 和 node manger 地址,与engineConnId、提交用户、ECM 实例 等封装一个FlinkJobInfo实例中。保存engineConnId和FlinkJobInfo实例的映射到缓存onceJobIdToJobInfo中。更新作业状态
类
TaskMonitorService中有个定时任务,从数据库中获取未完成的任务,根据任务的engineConnId从映射中拿到SubmittableSimpleOnceJob实例,内部会创建一个GetEngineConnAction,有 linkis 客户端发起请求,获取节点信息,里面包含了引擎的状态。
streamis 的失败日志
1 | 24129 2022-03-23 19:35:35.091 INFO [Linkis-Default-Scheduler-Thread-13] com.webank.wedatasphere.streamis.jobmanager.manager.service.TaskMonitorService 41 info - Try to update status of StreamJob-demo_flink_00. |
1 | 2022-04-19 10:59:35.091 INFO [Linkis-Default-Scheduler-Thread-14] com.webank.wedatasphere.streamis.jobmanager.manager.service.TaskMonitorService 41 info - Try to update status of StreamJob-demo_flink_00. |
这两种日志原因是一个,引擎执行失败。
EngineConnServer 启动过程中会有两个定时任务
org.apache.linkis.engineconn.acessible.executor.service.DefaultExecutorHeartbeatService会启动一个定时任务发送心跳nodeHeartbeatMsg,其中包含了执行器的状态,org.apache.linkis.manager.am.service.heartbeat.AMHeartbeatService#heartbeatEventDeal会来处理收到的心跳,将心跳NodeHeartbeatMsg处理成nodeMetrics,持久化到表linkis_cg_manager_service_instance_metrics中org.apache.linkis.manager.am.service.heartbeat.AMHeartbeatService这个定时任务会从数据库中获取EngineNode,检查状态,如果状态是完成(包括:Success/Failed/ShuttingDown),就会执行清理操作,通过 pid 将 EngineServer kill 掉,最后将 EngineNode 信息从数据库删除
streamis 查询的时候,如果数据库中的引擎信息还在,就会返回下面的日志;如果不在了,就是上面的错误。
那为什么引擎会执行失败呢?从 EngineServer 的日志中大致可以看到,失败有两个地方
FlinkCodeOnceExecutor 启动之后,有个等待启动的环节,这个方法
org.apache.linkis.engineconnplugin.flink.executor.FlinkOnceExecutor#waitToRunning,这个方法内部会通过clusterDescriptor.getJobStatus获取状态1
2
3
4
5
6public JobStatus getJobStatus() throws JobExecutionException {
if (jobId == null) {
throw new JobExecutionException("No job has been submitted. This is a bug.");
}
return bridgeClientRequest(this.executionContext, jobId, () -> clusterClient.getJobStatus(jobId), false);
}这里调用
clusterClient.getJobStatus(jobId)会抛出下面的异常1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1622/04/19 10:58:07 ERROR deployment.ClusterDescriptorAdapter: Job: 0ea16c3a35df0649d6100c14b18c33c6 operation failed!
22/04/19 10:58:07 ERROR executor.FlinkCodeOnceExecutor: Fetch job status failed! retried ++1...
LinkisException{errCode=16023, desc='Job: 0ea16c3a35df0649d6100c14b18c33c6 operation failed!', ip='10-177-198-114.test.dgtest01', port=33836, serviceKind='linkis-cg-engineconn'}
at org.apache.linkis.engineconnplugin.flink.client.deployment.ClusterDescriptorAdapter.bridgeClientRequest(ClusterDescriptorAdapter.java:136)
at org.apache.linkis.engineconnplugin.flink.client.deployment.ClusterDescriptorAdapter.getJobStatus(ClusterDescriptorAdapter.java:88)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkOnceExecutor$$anon$1$$anonfun$2.apply(FlinkOnceExecutor.scala:87)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkOnceExecutor$$anon$1$$anonfun$2.apply(FlinkOnceExecutor.scala:87)
at org.apache.linkis.common.utils.Utils$.tryCatch(Utils.scala:40)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkOnceExecutor$$anon$1.run(FlinkOnceExecutor.scala:87)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)Flink 获取结果超时,
org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor#doSubmit1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19override def doSubmit(onceExecutorExecutionContext: OnceExecutorExecutionContext,
options: Map[String, String]): Unit = {
// ...
future = Utils.defaultScheduler.submit(new Runnable {
override def run(): Unit = {
info("Try to execute codes.")
RelMetadataQueryBase.THREAD_PROVIDERS.set(JaninoRelMetadataProvider.of(FlinkDefaultRelMetadataProvider.INSTANCE))
Utils.tryCatch(CodeParserFactory.getCodeParser(CodeType.SQL).parse(codes).filter(StringUtils.isNotBlank).foreach(runCode)){ t =>
error("Run code failed!", t)
setResponse(ErrorExecuteResponse("Run code failed!", t))
tryFailed()
return
}
info("All codes completed, now stop FlinkEngineConn.")
trySucceed()
}
})
this synchronized wait()
}这里在
runCode中获取结果会超时,在方法tryFailed()将状态修改为 Failed。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
4222/04/19 10:59:13 ERROR executor.FlinkCodeOnceExecutor: Run code failed!
java.util.concurrent.ExecutionException: java.lang.RuntimeException: Failed to fetch next result
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at org.apache.flink.table.api.internal.TableResultImpl.awaitInternal(TableResultImpl.java:123)
at org.apache.flink.table.api.internal.TableResultImpl.await(TableResultImpl.java:86)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor.runCode(FlinkCodeOnceExecutor.scala:122)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1$$anonfun$run$1$$anonfun$apply$mcV$sp$2.apply(FlinkCodeOnceExecutor.scala:72)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1$$anonfun$run$1$$anonfun$apply$mcV$sp$2.apply(FlinkCodeOnceExecutor.scala:72)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1$$anonfun$run$1.apply$mcV$sp(FlinkCodeOnceExecutor.scala:72)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1$$anonfun$run$1.apply(FlinkCodeOnceExecutor.scala:72)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1$$anonfun$run$1.apply(FlinkCodeOnceExecutor.scala:72)
at org.apache.linkis.common.utils.Utils$.tryCatch(Utils.scala:40)
at org.apache.linkis.engineconnplugin.flink.executor.FlinkCodeOnceExecutor$$anon$1.run(FlinkCodeOnceExecutor.scala:72)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: Failed to fetch next result
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:109)
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.hasNext(CollectResultIterator.java:80)
at org.apache.flink.table.planner.sinks.SelectTableSinkBase$RowIteratorWrapper.hasNext(SelectTableSinkBase.java:117)
at org.apache.flink.table.api.internal.TableResultImpl$CloseableRowIteratorWrapper.hasNext(TableResultImpl.java:350)
at org.apache.flink.table.api.internal.TableResultImpl$CloseableRowIteratorWrapper.isFirstRowReady(TableResultImpl.java:363)
at org.apache.flink.table.api.internal.TableResultImpl.lambda$awaitInternal$1(TableResultImpl.java:110)
at java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java:1626)
... 3 more
Caused by: java.io.IOException: Failed to fetch job execution result
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.getAccumulatorResults(CollectResultFetcher.java:169)
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.next(CollectResultFetcher.java:118)
at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:106)
... 9 more
Caused by: java.util.concurrent.TimeoutException
at java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1771)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915)
at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.getAccumulatorResults(CollectResultFetcher.java:167)
... 11 more
上面的这个问题提了 issue,我个人的理解是:这是与 Flink 的 per-job 模式相关的,per-job 模式的特点的一个任务一个集群,任务运行完毕,集群就被销毁掉了,所以在任务结束后想获取任务状态和结果的行不通的。
解决
- Flink per job 模式下,任务执行结束后,通过回调返回状态
- streamis 以 session 模式提交
- streamis 直接查询 yarn 获取任务状态
这三种方案中,
第一个由于需要修改 flink 的代码,比较复杂,调用方(linkis)也要做相应修改,比如要传一个回调地址给 flink,要有处理回调的逻辑。
第二个,虽然可以解决 per job 模式下,任务运行结束后集群销毁的问题,但是产生更多的问题,比如 session 集群里面,可以执行多个任务,获取某一个任务的执行状态,需要额外的处理;由于多个任务同时运行在一个集群中,资源隔离也是个问题
关于第三个方案,从前面的分析中,在 streamis 提交任务的过程中,会从 linkis 获取一个
FlinkJobInfo,这个对象封装了 applicationId 和 applicationUrl,这个两个变量是在方法org.apache.linkis.engineconnplugin.flink.executor.FlinkOnceExecutor#submit1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19protected def submit(onceExecutorExecutionContext: OnceExecutorExecutionContext): Unit = {
ClusterDescriptorAdapterFactory.create(flinkEngineConnContext.getExecutionContext) match {
case adapter: T => clusterDescriptor = adapter
case _ => throw new ExecutorInitException("Not support ClusterDescriptorAdapter for flink application.")
}
val options = onceExecutorExecutionContext.getOnceExecutorContent.getJobContent.map {
case (k, v: String) => k -> v
case (k, v) if v != null => k -> v.toString
case (k, _) => k -> null
}.toMap
doSubmit(onceExecutorExecutionContext, options)
if(isCompleted) return
if (null == clusterDescriptor.getClusterID)
throw new ExecutorInitException("The application start failed, since yarn applicationId is null.")
setApplicationId(clusterDescriptor.getClusterID.toString)
setApplicationURL(clusterDescriptor.getWebInterfaceUrl)
info(s"Application is started, applicationId: $getApplicationId, applicationURL: $getApplicationURL.")
if(clusterDescriptor.getJobId != null) setJobID(clusterDescriptor.getJobId.toHexString)
}从日志中看到 applicationId 和 applicationURL 的取值
1
./linkis-cg-engineconnmanager.out:8e315be6-d4f5-4151-a02f-a54daa53c10b:22/04/19 10:56:52 INFO executor.FlinkCodeOnceExecutor: Application is started, applicationId: application_1644979452149_41155, applicationURL: http://10-177-198-117.ostream-test.dgtest01:36877
这里 applicationURL 是与任务绑定的(端口:36877),问题是任务跑结束后,这个端口的访问不了的。不过,已经有了 applicationId,通过 yarn 的接口就可以知道这个任务运行的结果。yarn 接口地址从哪里获取?
这个方法进来后,先会创建一个
clusterDescriptor,在 streamis 这个场景中,会创建一个org.apache.linkis.engineconnplugin.flink.client.deployment.YarnPerJobClusterDescriptorAdapter实例,它的父类org.apache.linkis.engineconnplugin.flink.client.deployment.ClusterDescriptorAdapter中有一个YarnClusterDescriptor类型的成员,这个类中有一个YarnClient对象yarnClient。yarnClient这个对象的创建会用到配置文件yarn-conf.xml,通过处理可以获取到配置文件中 resource manager 的地址,将这个地址保存到执行器中。当 streamis 来获取引擎信息的时候,设置到返回消息中,具体是这个方法
org.apache.linkis.engineconn.acessible.executor.operator.impl.EngineConnApplicationInfoOperator#apply1
2
3
4
5
6
7
8override def apply(implicit parameters: Map[String, Any]): Map[String, Any] = {
ExecutorManager.getInstance.getReportExecutor match {
case yarnExecutor: YarnExecutor =>
Map("applicationId" -> yarnExecutor.getApplicationId, "applicationUrl" -> yarnExecutor.getApplicationURL,
"queue" -> yarnExecutor.getQueue, "yarnMode" -> yarnExecutor.getYarnMode)
case _ => throw EngineConnException(20301, "EngineConn is not a yarn application, cannot fetch applicaiton info.")
}
}streamis 其实有将
FlinkJobInfo保存在表linkis_stream_task中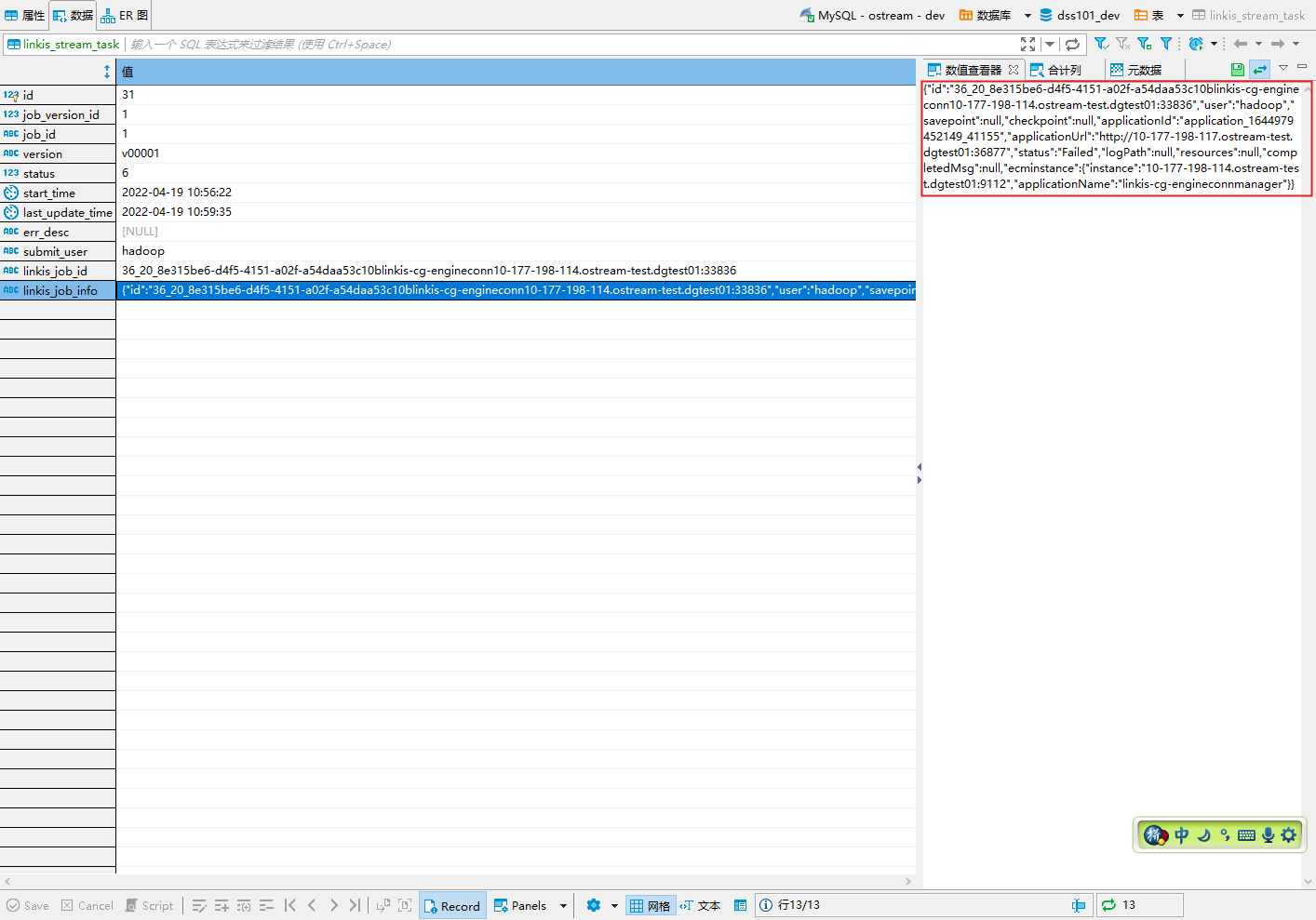
当
TaskMonitorService中的定时任务从表linkis_stream_task获取到需要更新状态的作业的,替换原来更新逻辑为调用保存的 yarn rm 地址查询对应的 applicationId 的状态。